Както знаете, компютърът съхранява информацията в двоична форма, представяйки я като последователност от единици и нули. За да преведе информацията в форма, която е удобна за човешкото възприятие, всяка уникална последователност от цифри, когато се показва, се заменя със съответния символ. Една от системите за корелация за двоични кодове с отпечатани и контролни знаци е ASCII кодирането. На днешното ниво на развитие на компютърните технологии от страна на потребителя не се изисква познаване на кода на всеки специфичен характер. Въпреки това, общото разбиране за това как е направено кодирането е изключително полезно, а за някои категории специалисти е абсолютно необходимо.
Създаване на ASCII
Оригиналното кодиране е разработено през 1963 г. и след това е актуализирано за 25 години. В оригиналната версия таблицата със символи ASCII включваше 128 символа, а по-късно се появи разширена версия, в която бяха запазени първите 128 символа, а кодовете с 8-ия бит съответстват на предишните непроверени символи.
В продължение на много години това кодиране беше най-популярното в света. През 2006 г. Латинска 1252 пое водещата роля, а от края на 2007 г. досега Unicode заема водеща позиция.
Подаване на ASCII компютър
Всеки ASCII символ има свой собствен код, състоящ се от 8 символа, представляващи нула или единица. Минималният брой в това представяне е нула (осем нули в двоичната система), което е кодът на първия елемент в таблицата.
МаксималноДвоичният код в оригиналната ASCII версия е нула + седем единици, а в разширената версия - осем единици, тъй като е свързан осмият бит.
Контролни символи
Контролните знаци се наричат не-графични изображения, използвани за организиране на текст, управление на устройства и др. Те могат да означават началото или края на текста, табулирането, генерирането на звуков сигнал, различните операции за телетип (телетип - машина за предаване на данни по електрически канал), разрешение за извеждане на данни към устройството, анулиране на действие и др.
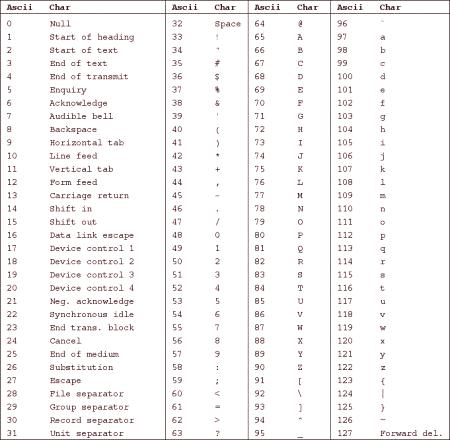
В таблицата със символи ASCII позициите от 0 до 31 и 127 се разпределят под контролните знаци. Общо за тези знаци 33.
Други символи
Останалите 95 позиции се разпределят за разделителни знаци и символи на математически операции, десетични цифри, букви от латинската азбука, които се различават в регистъра: "А" и "а" съответно съответстват на различни кодове на таблицата със символи ASCII.
Цифри от таблицата
Ако човек разработва софтуер или изпълнява други задачи в областта на информационните технологии, той трябва да знае номерата на поредица от ASCII символи. Както е споменато по-горе, позиции 0-31 и 127 заемат контролни символи. На номер 32 се задава интервал, номера 33-47 и 58-64 се присвояват на пунктуационни знаци и основни математически операции.
Латинските букви са подредени по азбучен ред и имат номера от 65-то до 90-то. Редове са подредени по азбучен ред, позициите им - от 97 до 122. Останалите числа (91-96 и 123-126) са фиксирани на квадратни и къдрави скоби,наклонена и права линия, както и някои диакритични знаци. На изображението по-горе може да се види пълна таблица със символи в удобно графично изображение. Фигурата по-долу показва броя на символите в руската таблица със символи ASCII.
Разширено ASCII
Тъй като изходният код е предназначен за американския потребител, той не предвижда не само различни видове писане и национални азбуки, но дори и удобното използване на диакритични знаци, използвани активно в европейските езици.
За генериране на разширено кодиране е използван 8-мият бит. Тази версия включва героите на националните европейски азбуки и фонетичната транскрипция, елементите на графиките, използвани за рисуване на таблици, поредица от математически знаци. Някои ASCII символи днес рядко се използват. По-специално, той се отнася до знаците, използвани за изготвяне на таблици, тъй като през годините от развитието на разширеното кодиране са въведени много по-удобни начини за графично представяне на таблици.
Национални версии на кодирането
При появата на разширен ASCII вариант за показване на национални азбуки бяха използвани преобразувани версии на кодирането, с руски, гръцки и арабски символи вместо латински. Два кода в таблицата бяха настроени да превключват между стандартния US-ASCII и неговия национален вариант.
След като ASCII започна да включва 128 и 256 символа, дистрибуцията се превърна в опциякодиране, при което оригиналната версия на таблицата се съхранява в първите 128 кода с нула 8 бита. В горната половина на таблицата се съхраняваха знаци от националното писмо (128-255-та позиция). Не е необходимо да знаете кодовете ASCII символи директно. Разработчикът на софтуера обикновено е достатъчен да знае номера на позицията в таблицата, така че ако е необходимо, да изчисли кода си, използвайки двоична система.
Руски език
След развитието в началото на 70-те години на кодировките за скандинавски езици, китайски, корейски, гръцки и др., Съветският съюз пое своята версия. Скоро 8-битов кодиращ вариант, наречен KOI8, запази първите 128 символни кода на ASCII и разпредели едни и същи позиции за буквите на националната азбука и допълнителни знаци. Unicode реализацията KOI8 доминираше в руския сегмент на интернет. Имаше варианти за кодиране както на руската, така и на украинската азбука.
ASCII въпроси
Тъй като броят на елементите дори в разширена таблица не надвишава 256, отсъстваше възможността за поставяне в едно кодиране на няколко различни скрипта. През 90-те Рунет изглежда имаше проблем с "krocozyabr", когато текстовете, написани от руски символи ASCII, не се показваха правилно. Проблемът беше несъответствието между кодовете на различните варианти на ASCII. Припомнете си, че позициите 128-255 могат да имат различни маркировки и при смяна на една кирилица в друга, всички букви от текста са заменени от други, с идентичен номер в другкодиращи версии.
Текущо състояние
С появата на Unicode популярността на ASCII рязко спадна. Причината за това се крие във факта, че новото кодиране позволява да се поставят символите на почти всички езици за писане. В този случай първите 128 символа от ASCII съответстват на едни и същи символи в кодировката Unicode.
През 2000 г. ASCII е най-популярното кодиране в Интернет и е използвано от 60% от Google индексираните уеб страници на Google. До 2012 г. делът на тези страници е спаднал до 17%, докато Unicode (UTF-8) се превърна в най-популярния източник на кодиране. По този начин ASCII е важна част от историята на информационните технологии, но използването му в бъдеще изглежда неперспективно.
 В продължение на много години това кодиране беше най-популярното в света. През 2006 г. Латинска 1252 пое водещата роля, а от края на 2007 г. досега Unicode заема водеща позиция.
В продължение на много години това кодиране беше най-популярното в света. През 2006 г. Латинска 1252 пое водещата роля, а от края на 2007 г. досега Unicode заема водеща позиция.