Звуковото кодиране се отнася до начините за съхраняване и предаване на аудио данни. Следващата статия описва как работят тези кодировки. Имайте предвид, че това е доста сложна тема - "Дълбочина на звуково кодиране". Дефинирането на тази концепция ще бъде дадено и в нашата статия. Представените в статията концепции са предназначени само за общ преглед. Нека разширим понятието за дълбочина на звуковото кодиране. Някои от тези препратки могат да бъдат полезни за разбирането на начина, по който работи API и как да се артикулира и обработва аудио във вашите приложения.
Как да намерите дълбочината на кодирането на звука
Аудио форматът не е еквивалентен на аудио кодиране. Например, един популярен файлов формат, като WAV, определя формата на заглавието на аудиофайла, но сам по себе си не е звуково кодиране. WAV файлове често, но не винаги използват линейно PCM кодиране. От своя страна FLAC е файлов формат и кодиране, което понякога води до известно объркване. В API FLAC на речта дълбочината на аудио кодиране е единственото кодиране, което изисква аудио данни да включват заглавна част. Всички други кодирания показват тихи аудио данни. Когато се отнасяме към FLAC в Speech API, винаги се отнасяме към кодека. Когато се отнасяме към формата на файла FLAC, ще използваме формата .LAC.
Не е необходимо да указвате кодирането и честотата на дискретизация за WAV или FLAC файлове. Ако тази опция е пропусната, APIът, базиран на облак, автоматично определя кодирането и честотата на дискретизация за WAV или FLAC файлове въз основа на заглавката на файла.Ако зададете стойност за кодиране или честота на дискретизация, която не съответства на стойността в заглавната част на API файла на облака, тя ще върне грешка.
Каква е дълбочината на кодирането на звука?
Аудиото се състои от осцилограми, състоящи се от интерполация на вълни с различни честоти и амплитуди. За да се представят тези форми на сигнали в цифрова среда, сигналите трябва да бъдат отхвърлени със скорост, която може да представлява звуците с най-високата честота, която искате да възпроизведете. За тях е необходимо също така да се поддържа достатъчна дълбочина на бита, за да се представят правилните осцилограми на амплитудата (обема и мекотата) въз основа на звуковата проба. Възможността за възпроизвеждане на честотата е известна като нейната честотна характеристика, а способността да се създаде подходящ обем и мекота е известна като динамичен обхват. Заедно тези термини често се наричат здравината на звуковото устройство. Дълбочината на звуковото кодиране е средство, чрез което можете да възстановите звука, използвайки тези два основни принципа, както и възможността за ефективно съхранение и предаване на такива данни.
Честота на вземане на проби
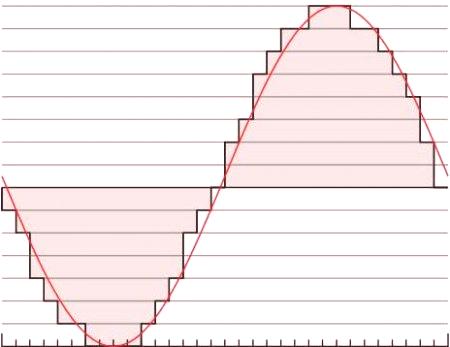
Звукът съществува като аналогова форма на вълната. Цифровият звуков сегмент се доближава до тази аналогова вълна и взема амплитудата му на сравнително висока скорост, за да симулира собствените си вълнови честоти. Честотата на дискретизация на цифров звук определя броя на пробите, взети от аудио изхода (във втора). Високата честота на дискретизация увеличава способността на цифровия звук да представлява точно високите честоти.
Като следствие от теорематаNyquist-Shannon, обикновено трябва да опитате поне два пъти честотата на всяка звукова вълна, която трябва да бъде записана цифрово. Например, за да се представи звук в обхвата на човешкия слух (20-20000 Hz), цифровото аудио трябва да показва поне 40 000 пъти в секунда (което е причината, поради която звукът на компактдиска използва честота на дискретизация 44100 Hz).
Depth Beat
Дълбочината на кодиране на звука е ефектът върху динамичния обхват на дадена звукова проба. По-високата битова дълбочина ви позволява да представяте по-точни амплитуди. Ако имате много силни и меки звуци в една и съща звукова проба, ще ви трябват повече бита, за да предадете правилно тези звуци. По-високите битови дълбочини също намаляват съотношението сигнал /шум в аудио-образците. Ако дълбочината на кодиране на звука е 16 бита, звукът от компактдиска се предава чрез тези стойности. Някои методи за компресиране могат да компенсират по-ниските битови дълбочини, но те обикновено са загубени. DVD Audio използва 24 бита дълбочина, докато повечето телефони имат 8-битова дълбочина на аудио кодиране.
Звук без звук
Голяма част от цифровата обработка на звука използва тези два метода (честота на дискретизация и дълбочина на битовете) за лесно съхранение на аудио данни. Една от най-популярните цифрови звукови технологии (популяризирана с CD) е известна като импулсно-кодова модулация (PCM). Аудиото се избира на определени интервали и амплитудата на дискретната вълна на тази точка се запаметява като цифрова стойност отизползване на битова дълбочина на пробата. Линейният PCM (който показва, че амплитудният отговор е линейно равномерен в извадката) е стандартът, използван на CD-та и в кодирането на LINEAR16 Speech API. И двете кодирания създават некомпресиран байтов поток, съответстващ директно на аудио данни, и двата стандарта съдържат 16 бита дълбочина. Linear PCM използва битрейт от 44100 Hz на компактдискове, които са подходящи за препозициониране на музика. Въпреки това, честотата на дискретизация от 16000 Hz е по-подходяща за преизчисляване на речта. Линеен PCM (LINEAR16) е пример за некомпресиран звук, тъй като цифровите данни се съхраняват по подобен начин. При четене на едноканален байт поток, кодиран с помощта на линеен PCM, можете да преброите всеки 16 бита (2 байта), за да получите друга стойност на амплитудата на сигнала. Почти всички устройства могат първо да манипулират такива цифрови данни - можете да отрежете Linear PCM аудио файловете с текстов редактор, но некомпресираният звук не е най-ефективният начин за транспортиране или съхраняване на цифров звук. Поради тази причина повечето аудио използват методи за цифрово компресиране.
Кратък звук
Аудио данните, като всички данни, често се компресират, за да се улесни съхранението и транспортирането. Компресирането в аудиокодирането може да стане без загуба или загуба. Компресията без загуби може да бъде разопакована, за да се възстановят цифровите данни в оригиналната форма. Компресията задължително изтрива част от информацията по време на процедурата за декомпресия и се параметризира, за да покаже степента на толерантност към техникатакомпресия за изтриване на данни.
Lossless
Цифровите потоци се компресират без загуба, като се използват сложни промени в съхранените данни, което не влошава качеството на оригиналната цифрова проба. В случай на некомпресирана компресия, при извличане на данни в оригиналната цифрова форма, информацията няма да бъде загубена. Така че, защо методи за компресия без загуби понякога имат опции за оптимизация? Тези настройки често обработват размера на файла за времето за декомпресия. Например, FLAC използва параметъра за ниво на компресия от 0 (най-бързо) до 8 (най-малкият размер на файла). Компресирането на FLAC на по-високо ниво няма да загуби никаква информация в сравнение с компресията на по-ниско ниво. Вместо това алгоритъмът на компресия просто ще трябва да похарчи повече изчислителна енергия при конструирането или разрушаването на оригиналния цифров звук. Speech API поддържа две кодировки без загуби: FLAC и LINEAR16. Технически, LINEAR16 не е "компресия без загуби", тъй като компресията не е основно свързана. Ако размерът на файла или преносът на данни са важни за вас, изберете FLAC като опция за аудио кодиране.
Загуба на компресия
Компресирането на аудио данни елиминира или намалява някои видове информация при конструирането на компресирани данни. Speech API поддържа множество формати за загуби, въпреки че те трябва да се избягват, тъй като загубата на данни може да повлияе на точността на разпознаването.
Популярният MP3 кодек е пример за метод за кодиране със загуба. Всички методи за компресиране на MP3 премахват звука от външната страна на нормалната човешка аудио лента и регулират нивото на компресия чрез ефективно регулиранеMP3 кодек или битово число в секунда, за да запазите датата на звука. Например, стерео компактдиск, използващ линеен PCM с 16 бита, има ефективна скорост на битовете. Формат на дълбочината на кодиране на звука: 441000 * 2 канала * 16 бита = 1411200 бита в секунда (бит /сек) = 1411 kbit /s Например, MP3 компресията премахва такива цифрови данни, като използва скорост на предаване на данни като 320 kbps, 128 kbps /s или 96 kbit /s, което води до лошо качество на звука. MP3 също така поддържа променливи битови скорости, които могат да компресират аудио. И двата метода губят информация и могат да повлияят на качеството. Може да се каже, че повечето хора могат да определят разликата между 96kbps или 128kbps кодирана MP3 музика.
Други форми на компресиране
MULAW е 8-битово PCM кодиране, където амплитудата на извадката се модулира логаритмично, а не линейно. В резултат uLaw намалява ефективния динамичен обхват на компресирания звук. Въпреки че uLaw е въведена специално за оптимизиране на кодирането на речта, за разлика от други аудио типове, 16-битовият LINEAR16 (некомпресиран PCM) все още е много по-добър от 8-битовия компресиран звук на uLaw. AMR и AMR_WB модулират кодираната аудиокасета, като въвеждат променливата битова скорост в изходния звук.
Въпреки че Speech API поддържа множество формати за загуби, трябва да ги избягвате, ако имате контрол върху оригиналния звук. Въпреки че премахването на такива данни чрез компресия на загуби може да не окаже значителен ефект върху звука, чуван от човешкото ухо, загубата на такива данни за механизма за разпознаване на речможе значително да влоши точността.