Изкуственият интелект и невронните мрежи са невероятно вълнуващи и мощни методи, основани на машинно обучение, които се използват за решаване на реални проблеми. Най-простият пример за невронна мрежа е изучаването на пунктуацията и граматиката, за да се създаде напълно нов текст с прилагането на всички правила на правописа.
История на невронната мрежа
Учените в областта на компютъризацията отдавна се опитват да симулират човешкия мозък. През 1943 г. Warren S. McCullough и Walter Pitts разработиха първия концептуален модел на изкуствената невронна мрежа. В статията "Логическият брой идеи, свързани с нервната дейност", те описват примера на невронна мрежа, концепцията за неврон - една клетка, живееща в общата мрежа, получава входни данни, обработва ги и генерира изходни сигнали.
Тяхната работа, подобно на много други учени, не е била предназначена да описва точно работата на биологичния мозък. Изградена е изкуствена невронна мрежа като изчислителен модел, който работи на принципа на мозъчната функция за решаване на широк спектър от задачи. Очевидно е, че има упражнения, които са лесни за решаване за компютър, но са трудни за човека, например извличане на квадратен корен от десетцифрено число. Този пример ще изчисли невронната мрежа за по-малко от една милисекунда, а човекът има нужда от минути. От друга страна, има такива, които са невероятно лесни за решаване на човек, но не под силата на компютър, например, за да изберете фоновото изображение.
Учените са прекарали много време в проучване и прилагане на комплексни решения. Най-често срещаният пример за невронна мрежа в компютрите е разпознаването на образи. Обхватът варира от оптично разпознаване на символи и отпечатване на снимки, или ръкописните сканирания към цифров текст, за да разпознаят лицето.
Биологични калкулатори
Човешкият мозък е изключително сложен и най-мощният от известните компютри. Неговата вътрешна работа е моделирана около концепцията за невроните и техните мрежи, известни като биологични невронни мрежи. Мозъкът съдържа около 100 милиарда неврони, които са свързани с тези мрежи. На високо ниво те взаимодействат помежду си чрез интерфейс, който се състои от аксонови терминали, свързани с дендрити през космически синапс. Говорейки на обикновен език, човек предава съобщение на друг през този интерфейс, ако сумата на претеглените входове от един или повече неврони надвишава прага за задействане на предаването. Това се нарича активиране, когато прагът е превишен, и съобщението се предава на следващия неврон. Процесът на сумиране може да бъде математически сложен. Входният сигнал е претеглена комбинация от тези сигнали, а претеглянето на всеки от тях означава, че този вход може да има различен ефект върху последващите изчисления и крайния изход на мрежата.
Елементи на невронния модел
Дълбокото обучение е терминът, използван за сложни невронни мрежи, състоящи се от няколко слоя. Слоевете се състоят от възли. Node е просто място, къдетоима изчисление, което действа, когато се сблъскат с достатъчно стимули. Възелът интегрира входни данни от набор от коефициенти или тегла, които или усилват, или отслабват този сигнал, като по този начин определят значението на задачата. Мрежите с дълбоко обучение се различават от общия неврон с един скрит слой. Пример за обучение на невронни мрежи - мрежата на Кохонен.
В мрежи с дълбоко обучение всеки слой разпознава определен набор от функции въз основа на оригиналната информация от предишното ниво. По-нататъшното преминаване в невронната мрежа, толкова по-трудни обекти, които могат да бъдат разпознати от възлите, тъй като те комбинират и рекомбинират обекти от предишното ниво. Мрежите за дълбоко обучение извършват автоматично извличане на функции без човешка намеса, за разлика от повечето традиционни алгоритми и завършват с първоначално ниво: логически или softmax-класификатор, който определя вероятността от конкретен резултат и се нарича прогноза.
Black Box ANN
Изкуствените невронни мрежи (SNN) са статистически модели, които са частично моделирани в биологични невронни мрежи. Те могат да се справят паралелно с нелинейната връзка между входовете и изходите. Такива модели се характеризират с наличието на адаптивни тежести по протежение на пътеките между невроните, които могат да бъдат конфигурирани от алгоритъма за обучение за подобряване на целия модел.
Един прост пример за невронна мрежа е архитектурно изкуствена неврална мрежа на АНМ, където:
Входният слой е входен слой.
Скритият слой е скрит слой.
Изходящ слой - Изходен слой.
Той е моделиран с помощта на слоеве от изкуствени неврони или изчислителни единици, способни да приемат входящи данни и да използват активираща функция заедно с прагови стойности, за да определят дали съобщенията се предават или изпращат. В един прост модел първият слой е входният сигнал, който трябва да бъде скрит и накрая изхода. Всеки един може да съдържа един или повече неврони. Моделите могат да станат все по-сложни с увеличаване на абстракцията и решаването на проблеми, броя на скритите слоеве, броя на невроните във всеки слой и броя на песните между тях. Архитектурата и моделирането на модела са основните компоненти на методите на МНС в допълнение към самите алгоритми на обучение. Те са изключително мощни и се считат за алгоритми за черна кутия, което означава, че тяхната вътрешна работа е много трудна за разбиране и обяснение.
Дълбоки алгоритми на обучение
Дълбоко обучение - тази концепция звучи доста шумно, всъщност, тя е просто термин, който описва някои видове невронни мрежи и свързани алгоритми, които консумират сурови входни данни чрез набора от слоеве от нелинейни преобразувания за изчисляване целеви изход Непривлекателна черта на характеристиките е и област, в която дълбокото обучение надхвърля всички очаквания. Пример за преподаване на невронни мрежи - SKIL мрежи.
Традиционно, един учен или програмист на данни попада под отговорността да изпълнява процеса на извличане на атрибути в повечето други подходи за машинно обучение заедно с избора на функции и дизайн.
Оптимални параметри на алгоритъма
АлгоритмиУчебните функции позволяват на машината да научи конкретна задача, използвайки ограничен набор от възможности за учене. С други думи, те се учат да учат. Този принцип се използва успешно в много приложения и се счита за един от напредналите методи за изкуствен интелект. Подходящи алгоритми често се използват за контролирани, неконтролируеми и частично контролирани задачи. В моделите, базирани на невронната мрежа, броят на слоевете е по-голям, отколкото в алгоритмите за повърхностно обучение. Малките алгоритми са по-малко сложни и изискват по-задълбочено познаване на оптималните функции, които включват избор и развитие. Напротив, дълбоките алгоритми за обучение разчитат повече на оптималния избор на модел и неговата оптимизация чрез персонализиране. Те са по-подходящи за решаване на проблеми, когато предварителното познаване на функциите е по-малко желано или необходимо и фиксираните данни са недостъпни или не са необходими за използване. Входните данни се превръщат във всички слоеве, като се използват изкуствени неврони или процесорни блокове. Пример за код на невронна мрежа се нарича CAP.
Стойността на ОСП
ОСП се използва за измерване на архитектурата на модела за дълбоко обучение. Повечето изследователи в тази област са съгласни, че той има повече от два нелинейни слоя за ОСП, докато някои смятат, че ОСП, която има повече от десет слоя, изисква твърде много обучение.
Подробно обсъждане на многото различни архитектури на моделите и алгоритмите на този вид обучение е много пространствено и противоречиво. Най-изучени са:
Директноневронни мрежи.
Релатираща невронна мрежа.
Многослоен персептрон (MLP).
Rolling Neural Networks.
Рекурсивни невронни мрежи.
Дълбоки мрежи от вярвания.
Подвижна мрежа от дълбоки убеждения.
Самоорганизиращи се карти.
Дълбоки коли на Болцман.
Съставени авто-енкодери, излъчващи шум.
Най-модерни архитектури
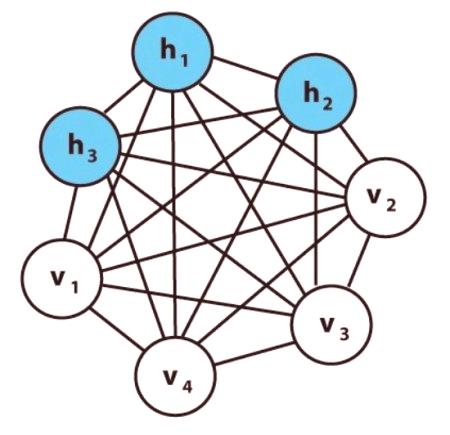
Перцептоните се считат за невронни мрежи от първо поколение, изчислителни модели на един неврон. Те са изобретени през 1956 г. от Франк Розенблат в "Perceptron: Предсказуем модел на съхранение и организация на информацията в мозъка". Перцептронът, наричан още мрежата за директна връзка, предава информация от предната към задната част. Периодични невронни мрежи RNN преобразуват входната последователност в изхода, който е в друга област, например, променя последователността на звуковите налягания в последователността на думите. Джон Хопфилд въведе Hopfield Net в статия от 1982 г. "Невронни мрежи и физически системи с нововъзникващи възможности за колективни изчисления". В мрежата на Хопфилд (HN), всеки неврон е свързан с всеки друг. Те се учат, като задават стойността си на желаната схема, след което можем да изчислим коефициентите на тегло.
Машината на Болцман е вид стохастична рекурентна невронна мрежа, която може да се разглежда като аналог на мрежите на Хопфилд. Това беше един от първите варианти за изучаване на вътрешни представи, които решават сложни комбинаторни проблеми.Входящите неврони стават изход в края на пълната актуализация. Общата конкурентна мрежа, Jan Goodfellow (GAN), се състои от две мрежи. Често това е комбинация от фуражните и конволюционните невронни мрежи. Единият генерира съдържание общо, а другото трябва да оценява съдържанието дискриминационно.
Получаване на SKIL от Python
Дълбокото изучаване на невронна мрежа в примера на Python сравнява входовете с изходите и намира корелации. Той е известен като универсален апроксиматор, защото може да се научи да носи неизвестната функция f (x) = y между всеки вход "x" и който и да е "y" изход, приемайки, че те са корелирани или причинени "yazkom. В процеса на обучение, правилното "f" или методът на преобразуване на "x", "y", било то f (x) = 3x + 12 или f (x) = 9x - 01. Задачите за класификация са свързани с наборите от данни, така че невронните мрежи извърши корелация между етикети и данни. Известно контролирано обучение от следните видове:
признаване на лица;
Идентифициране на хората в образи;
определяне на израза на лицето: ядосан, радостен;
идентифициране на обекти върху изображения: знаци за спиране, пешеходци, маркери за ленти;
разпознаване на жестове в видео;
определяне на гласа на ораторите;
класификация на спам текст.
Пример за конволюционална невронна мрежа
Конволюционната невронна мрежа е подобна на многослойна мрежа от перцептрони. Основната разлика е, че CNN проучва как е структурирана и с каква цел се използва. Вдъхновението за CNN е биологичните процеси. Тяхната структура има външния вид на зрителната кора, намираща се в животното.Те се прилагат в областта на компютърната визия и успешните постижения на съвременните нива на производителност в различни области на научните изследвания. Преди да започнат да кодират CNN, за изграждане на модела се използва библиотека, например Keras с бекенда на Tensorflow. Първо, направете необходимия внос. Библиотеката помага за изграждането на конволюционна невронна мрежа. Изтеглете mnist набора чрез keras. Импортирайте сериен keras модел, който може да добавя слоеве и сливане, плътни слоеве, тъй като те се използват за предсказване на етикети. Падащият слой намалява преоборудването и нивелирането превръща триизмерния вектор в едномерно. И накрая, вмъкнете numpy за матрични операции:
Y = 2 # стойност 2 представлява, че изображението има цифра 2;
Y = [0,0,1,0,0,0,0,0,0,0] # 3 позиция във вектора е направена 1;
# Тук стойността на класа се превръща в матрица на двоичен клас.
Алгоритъм на конструиране:
Добавете към последователния модел точните слоеве на максималния пул.
Добавете слоеве между тях. Падащият случайно разединява някои неврони в мрежата, което принуждава данните да откриват нови пътища и намалява преоборудването.
Добавете плътни слоеве, които се използват за предсказване на клас (0-9).
Съставете модел с категорична функция за кръстосана ентропия, оптимизатор на Adadelta и показател за точност.
След обучението се оценява загубата и точността на модела в съответствие с данните от изпитването и се отпечатва.
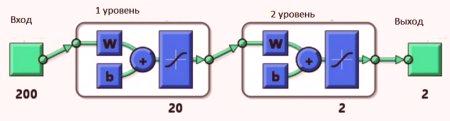
Моделиране в Matlab
Ето един прост пример за неутралните мрежи на Matlab-моделиране. Ако приемем, чече моделът "а" има три входа "а", "б" и "в" и генерира изход "у".
За целите на генерирането на данни: = 5a + bc + 7s. Първо напишете малък скрипт за генериране на данни:
a = Rand (11000);
б = бряг (11000);
с Rand (11000);
n = Rand (11000) * 005;
y = a * 5 + b * c + 7 * с + n,
където n е шум, специално добавен, за да изглежда като реални данни. Стойността на шума е 01 и е еднаква. По този начин, входът е набор от "а", "б" и "в" и заключение:
I = [a; б; с];
O = y.
След това използвайте вградената функция matlab newff за генериране на модела.
Примери за задачи на невронната мрежа
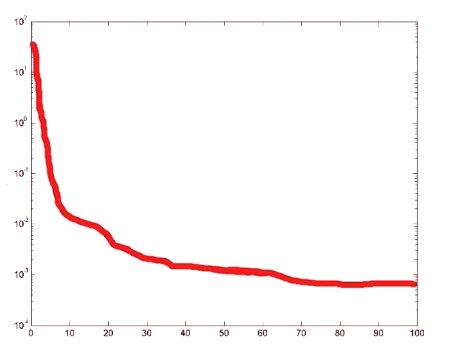
Първоначално се създава матрица R с размер 3 * 2. Първата колона показва минимум от трите входа, а втората - максимум три входа. В този случай трите входа са в диапазона от 0 до 1 за: R = [0 1; 0 1; 0 1]. Сега създайте матрица с размер, който има v-размер на всички слоеве: S = . Сега извикайте функцията newff както следва: net = newff ([0 1, 0 1; 0 1], S, {'tansig', 'purelin'}). Моделът на неврон {tansig ',' purelin 'показва функцията за показване на два слоя. Учете го с данните, създадени по-рано: net = train (net, I, O). Мрежата е обучена, можете да видите кривата на производителността, както се научава.
Сега отново го симулира на същите данни и сравнение на източника на данни: O1 = sim (нето, I); участък (1: 1000 О, 1: 1000 О1). Така, входната матрица ще бъде:
net.IW {1}
-036840.0308 -05402
046400.234005875
19569 -168871.5403
111381.084102439
net.LW {21}
-1119909.4589 -10006 -09138
Програми за изкуствен интелект
Примери за внедряване на невронната мрежа включват онлайн решение за самообслужване и създаваненадеждни работни потоци. Има дълбоки модели на обучение, използвани за чат ботове, тъй като те продължават да се развиват, може да се очаква, че тази област ще бъде по-използвана от широк кръг предприятия. Области на приложение:
Автоматичен машинен превод. Това не е нещо ново, дълбокото обучение помага да се подобри автоматичният превод на текста с помощта на сложни мрежи и ви позволява да преведете изображението.
Един прост пример за използване на невронни мрежи - добавяне на цвят към черно-бели изображения и видеоклипове. Тя може да се извърши автоматично, като се използват модели за задълбочено проучване.
Машините изучават пунктуация, граматика и стил на част от текста и могат да използват разработения от тях модел за автоматично създаване на напълно нов текст с правилен правопис, граматика и стил на текста. Изкуствени невронни мрежи и по-сложни техники за дълбоко обучение са някои от най-модерните инструменти за решаване на сложни задачи. Въпреки че приложението на бум е малко вероятно в близко бъдеще, напредъкът на технологиите и приложенията на изкуствения интелект със сигурност ще бъде очарователен. Въпреки факта, че дедуктивните разсъждения, логическите заключения и вземането на решения с помощта на компютър днес са все още далеч от съвършенство, е постигнат значителен напредък в прилагането на методи за изкуствен интелект и свързани алгоритми.
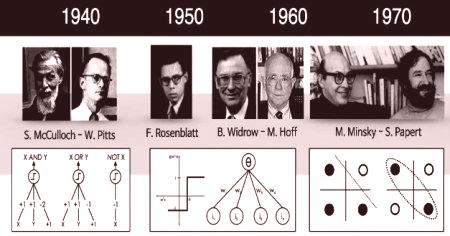 Тяхната работа, подобно на много други учени, не е била предназначена да описва точно работата на биологичния мозък. Изградена е изкуствена невронна мрежа като изчислителен модел, който работи на принципа на мозъчната функция за решаване на широк спектър от задачи. Очевидно е, че има упражнения, които са лесни за решаване за компютър, но са трудни за човека, например извличане на квадратен корен от десетцифрено число. Този пример ще изчисли невронната мрежа за по-малко от една милисекунда, а човекът има нужда от минути. От друга страна, има такива, които са невероятно лесни за решаване на човек, но не под силата на компютър, например, за да изберете фоновото изображение.
Тяхната работа, подобно на много други учени, не е била предназначена да описва точно работата на биологичния мозък. Изградена е изкуствена невронна мрежа като изчислителен модел, който работи на принципа на мозъчната функция за решаване на широк спектър от задачи. Очевидно е, че има упражнения, които са лесни за решаване за компютър, но са трудни за човека, например извличане на квадратен корен от десетцифрено число. Този пример ще изчисли невронната мрежа за по-малко от една милисекунда, а човекът има нужда от минути. От друга страна, има такива, които са невероятно лесни за решаване на човек, но не под силата на компютър, например, за да изберете фоновото изображение. 

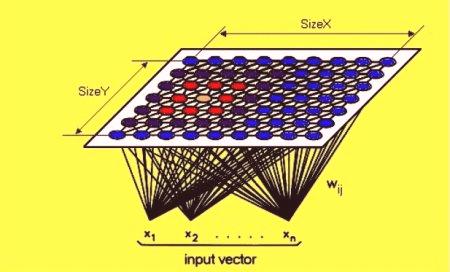
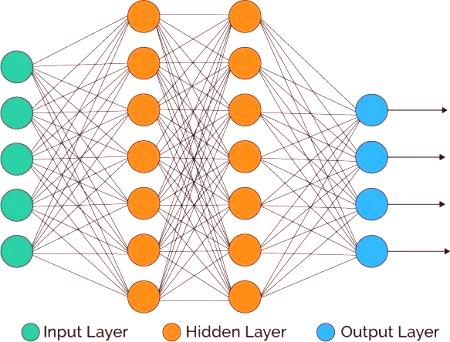

 Подробно обсъждане на многото различни архитектури на моделите и алгоритмите на този вид обучение е много пространствено и противоречиво. Най-изучени са:
Подробно обсъждане на многото различни архитектури на моделите и алгоритмите на този вид обучение е много пространствено и противоречиво. Най-изучени са: