Как да стигнем до курсове по SEO-промоция, новаците се срещат с голям брой разбираеми и не много навременни. Всичко това не е лесно да се разбере, особено ако първоначално е било слабо обяснено или изгубено някои от моментите. Помислете за стойността в файла robots.txt Disallow, който изисква този документ, как да го създадете и да работите с него.
С прости думи
За да не се "хранят" читателите със сложни обяснения, които обикновено се намират на специализирани сайтове, е по-добре да се обясни всичко "на пръстите". Търсачката пристига на вашия сайт и индексира страниците. След като видите отчети, които сочат към проблеми, грешки и др.
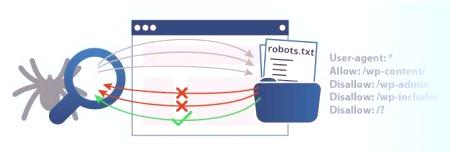
Но сайтовете също имат такава информация, която не се изисква за статистиката. Например страницата „Фирма“ или „Контакти“. Всичко това не е задължително за индексиране, а в някои случаи е нежелателно, защото може да наруши статистиката. За да избегнете това, най-добре е да затворите тези страници от робота. Именно това изисква команда от файла robots.txt Disallow.
Стандарт
Този документ е винаги достъпен на обектите. Създаването му се извършва от разработчици и програмисти. Понякога това може да се направи и от собствениците на ресурса, особено ако е малък. В този случай работата с него не отнема много време. Robots.txt се нарича стандарт за изключване на търсещи машини. Той е представен с документ, в който са предписани основните ограничения. Документът се поставя в основата на ресурса. В този случай, така че да може да бъде намерен по пътя "/robots.txt". акоресурсът има няколко поддомейни, след което този файл се поставя в основата на всеки от тях. Стандартът е непрекъснато свързан с друг - Sitemap.
Карта на сайта
За да се разбере пълната картина на това, което се обсъжда, няколко думи за Sitemap. Това е файл, написан на XML. Той съхранява всички данни за ресурса за PS. С документ можете да научите за уеб страници, индексирани от произведения.
Файлът осигурява бърз достъп до PS към всяка страница, показва последните промени, честотата и важността на PS. Според тези критерии роботът най-правилно сканира сайта. Но е важно да се разбере, че наличието на такъв файл не гарантира, че всички страници са индексирани. Това е по-скоро намек за пътя към този процес.
Употреба
Правилният файл robots.txt се използва доброволно. Самият стандарт се появи през 1994 година. Той бе приет от консорциума W3C. От този момент започва да се използва в почти всички търсачки. Той е необходим за "дозираната" настройка на сканирането на ресурси от търсещия робот. Файлът съдържа набор от инструкции, които използват FP. Благодарение на инструментариума е лесно да инсталирате файлове, страници, директории, които не могат да бъдат индексирани. Robots.txt също сочи към файлове, които трябва да бъдат проверени веднага.
Защо?
Въпреки факта, че файлът може да бъде използван доброволно, той се създава от почти всички сайтове. Това е необходимо, за да се рационализира работата на робота. В противен случай ще провери всички страници в произволен ред и освен че може да пропусне някои страници, ще създаде тежък товарресурс. Освен това файлът се използва за скриване от очите на търсачката:
Страници с лични данни на посетителите.
Страници, съдържащи формуляри за изпращане на данни и др.
Огледални сайтове.
Страници с резултати от търсенето.
Ако сте задали файл robots.txt Disallow за определена страница, има вероятност той все още да се показва в търсачката. Тази опция може да възникне, ако връзка към страница е поставена на един от външните ресурси или в сайта ви.
Директиви
Говорейки за забрана на търсачката, често се използва терминът "директиви". Този термин е познат на всички програмисти. Той често се заменя със синоним на "инструкция" и се използва във връзка с "команди". Понякога тя може да бъде представена от набор от конструкции на език за програмиране. Директивата Disallow в robots.txt е една от най-често срещаните, но не и единствените. Освен това има няколко други, които са отговорни за определени инструкции. Например, има потребителски агент, който показва роботи на търсачката. Позволете е противоположната команда за забрана. Той показва разрешението за обхождане на някои страници. След това нека разгледаме основните команди.
Визитка
Разбира се, в файла robots.txt, User Agent Disallow не е единствената директива, а една от най-често срещаните. Състои се от по-голямата част от файловете за малки ресурси. Визитна картичка за всяка система все още е команда за потребителски агент. Това правило е предназначено да сочи към роботи, които разглеждат инструкциите, които ще бъдат записани в документа. В момента има 300 търсачки. Ако искате всеки от тях да следваПо някакъв начин не бива да се презаписва почти нищо. Достатъчно е да посочите "User-agent: *". "Звездичка" в този случай ще покаже системи, че такива правила са предназначени за всички търсачки. Ако създавате указания за Google, трябва да посочите име на робот. В този случай използвайте Googlebot. Ако в документа е посочено само името, тогава другите търсачки няма да приемат командите на файла robots.txt: Disallow, Allow и др. Те ще приемат, че документът е празен и няма инструкции за тях.
Пълен списък на botnam може да бъде намерен в интернет. Той е много дълъг, така че ако имате нужда от инструкции за определени услуги на Google или Yandex, ще трябва да посочите конкретни имена.
Забрана
Вече много пъти говорихме за следващия екип. Disallow само указва каква информация не трябва да се чете от робота. Ако искате да покажете на търсещите машини цялото си съдържание, напишете "Disallow:". Така че работата ще сканира всички страници на вашия ресурс. Пълната забрана за индексиране на robots.txt "Disallow: /". Ако напишете по този начин, то работата няма да сканира ресурса изобщо. Това обикновено се прави в началните етапи, в подготовка за стартиране на проекта, в експерименти и др. Ако сайтът е готов да се покаже, променете тази стойност, така че потребителите да могат да се запознаят с него. Като цяло екипът е универсален. Тя може да блокира определени елементи. Например, папка с командата Disallow: /papka /може да забрани да обхожда връзка към файл или документи с конкретно разрешение.
Разрешение
Да се разреши работапреглеждайте определени страници, файлове или директории, използвайки директивата Allow. Понякога е необходима команда, за да може роботът да посети файлове от определен раздел. Например, ако това е онлайн магазин, можете да посочите директория. Ще бъдат сканирани и други страници. Но не забравяйте, че първо трябва да спрете сайта да преглежда цялото съдържание и след това да зададете командата Разреши с отворените страници.
Огледала
Друга директива за домакините. Не се използва от всички уебмастъри. Това е необходимо, ако вашият ресурс има огледала. Тогава това правило е задължително, тъй като то показва работата на "Yandex", на коя от огледалата е основната и която трябва да бъде сканирана. Системата не се отклонява от себе си и лесно намира необходимия ресурс съгласно инструкциите, описани в robots.txt. В самия файл сайтът е написан без индикация "http: //", но само ако работи на HTTP. Ако той използва протокола HTTPS, той посочва този префикс. Например, "Хост: site.com", ако е HTTP, или "Хост: https://site.com" в случай на HTTPS.
Navigator
Вече говорихме за Sitemap, но като отделен файл. Разглеждайки правилата за писане на robots.txt с примери, виждаме използването на подобна команда. Файлът се отнася за „Sitemap: http://site.com/sitemap.xml“. Това се прави така, че роботът проверява всички страници, които са изброени на картата на сайта на адреса. Всеки път, когато се върнете, роботът ще вижда нови актуализации, направени промени и по-бързо изпращане на данни до търсачката.
Допълнителни команди
Това са основните насоки, които сочат към важните и необходими команди. Има по-малко полезни такиваИнструкциите не винаги се използват. Например закъснението при обхождане указва периода, който ще се използва между зареждането на страници. Това е необходимо за слаби сървъри, така че да не ги "постави" в роботите на роботите. За определяне на параметъра се използват секунди. Clean-param помага да се избегне дублирането на съдържание, което се намира на различни динамични адреси. Те възникват, ако има функция за сортиране. Това ще изглежда така: "Clean-param: ref /catalog/get_product.com".
Universal
Ако не знаете как да създадете правилния файл robots.txt - не е страшно. Освен инструкциите има и универсални версии на този файл. Те могат да бъдат поставени на почти всеки уебсайт. Изключение може да бъде само голям ресурс. Но в този случай досиетата трябва да са известни на специалистите и да ги ангажират в специални хора.
Универсален набор от директиви ви позволява да отворите съдържанието на сайта за индексиране. Тук има име на хост и е показана картата на сайта. Тя позволява на роботите винаги да имат достъп до страниците, които трябва да бъдат сканирани. Предполага се, че данните могат да варират в зависимост от системата, с която разполага ресурсът ви. Следователно, правилата трябва да бъдат избрани, като се погледне типа на сайта и CMS. Ако не сте сигурни, че файлът, който сте създали, е правилен, можете да го проверите в Google Webmaster Tools и Yandex.
Грешки
Ако разбирате какво означава Disallow в robots.txt, това не гарантира, че няма да правите грешки при създаването на документ. Има редица типични проблеми, с които се сблъскват неопитни потребители. Често се бърка стойността на директивата. Може да е такае свързано с неразбиране и с незнание на инструкциите. Може би просто сте го пренебрегнали и сте прекъснали небрежността. Например, те могат да използват "/" за User-agent, а за Disallow името е робот. Прехвърлянето е друга често срещана грешка. Някои потребители смятат, че изброяването на забранени страници, файлове или папки трябва да се показва един по един подред. Всъщност за всяка забранена или допустима връзка, файл и папка трябва да напишете командата отново и от новата линия. Грешките могат да бъдат причинени от грешното име на самия файл. Не забравяйте, че тя се нарича "robots.txt". Използвайте малките букви за името, без варианти като "Robots.txt" или "ROBOTS.txt".
Полето за потребителски агент трябва винаги да се попълва. Не оставяйте тази директива без команда. Когато се връщате отново на хоста, не забравяйте, че ако сайтът използва HTTP, не е необходимо да го указвате в командата. Само ако това е разширена версия на HTTPS. Не можете да оставите директивата Disallow безсмислена. Ако не ви трябва, просто не го сочи.
Заключения
Обобщавайки, струва си да се каже, че robots.txt е стандарт, който изисква точност. Ако никога не сте го срещали, то в ранните етапи на творението ще имате много въпроси. Най-добре е да дадете тази работа на уебмастъри, защото те работят с документа през цялото време. Освен това може да има някои промени в възприемането на директивите от търсачките. Ако имате малък сайт - малък онлайн магазин или блог - тогава ще е достатъчно да проучите този въпрос и да вземете един от универсалните примери.