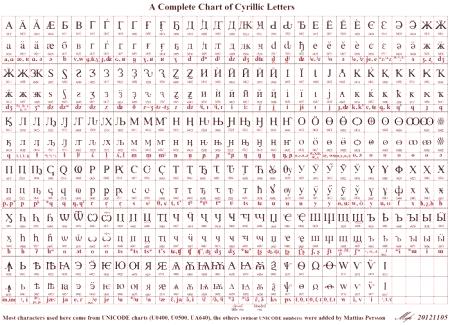
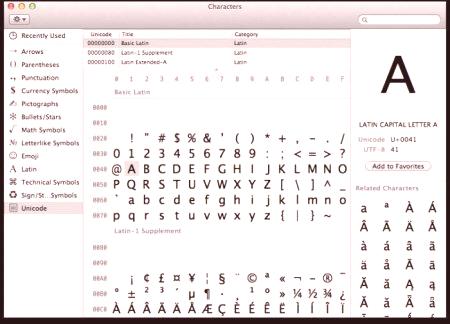
Unicode е международен стандарт за кодиране на символи, който ви позволява да показвате текст на всеки компютър в света по същия начин, независимо от езика на системата, използван в него.
Основи
За да разберем какво е необходима за Unicode таблицата със знаци, нека първо разберем механизма на показване на текст на екрана на монитора. Компютърът, както знаем, обработва цялата информация цифрово, но за да го изведе за правилното възприятие на човек трябва да бъде в графиката. Така че, за да можем да четем този текст, трябва да решим поне две задачи:
Кодираме отпечатаните знаци в цифрова форма. Да се даде възможност на операционната система да сравни цифровата форма с векторни символи, с други думи, за да намери правилните букви. Първо кодиране
Предшественикът на всички кодировки се счита за американския ASCII. Той описва английската азбука с пунктуация и арабски цифри. Използваните в него 128 символа станаха основа за по-нататъшно развитие - дори се използва съвременната Unicode таблица със знаци. Оттогава буквите от латинската азбука заемат първите позиции във всяко кодиране.
Всички ASCII разрешиха 256 символа да бъдат запазени, но тъй като първите 128 бяха латински, останалите 128 бяха използвани глобално за създаване на национални стандарти. Например, в Русия, на негова основа са създадени CP866 и KOI8-R. Тези варианти се наричаха разширенияASCII версии.
Кодирани страници и Crazzybras
По-нататъшното развитие на технологиите и появата на графичен интерфейс доведоха до създаването на ANSI кодиране от Американския институт за стандартизация. За руските потребители, особено с опит, версията му е известна като Windows 1251. За първи път е въведена концепцията за "кодова страница". Именно с помощта на кодови страници, съдържащи символи на национални азбуки, с изключение на латински, имаше „взаимно разбиране“ между компютрите, използвани в различни страни.
Въпреки това, наличието на голям брой различни кодировки, използвани за един и същ език, започна да причинява проблеми. Имаше така наречените каркозибриси. Те произтичат от несъответствието между изходната кодова страница, на която е създадена някаква информация, и кодовата страница, която се използва по подразбиране на компютъра на крайния потребител.
Като пример могат да бъдат цитирани гореспоменатите кирилисни кодировки CP866 и KOI8-R. Буквите в тях се различават по кодови позиции и принципи на разположение. В първия те бяха подредени по азбучен ред, а във втория - произволно. Можете да си представите какво се случва пред очите на потребителя, който се е опитал да отвори такъв текст, без да има кодовата страница, която искате или неправилно тълкуване от компютъра.
Създаване на Unicode
Разпространението на интернет и свързаните с него технологии, като електронна поща, доведе до факта, че текстовите съобщения в крайна сметка престанаха да отговарят на всички. Водещи компании в областтаIT създаде Unicode Consortium (Unicode Consortium), символна таблица, въведена от него през 1991 г. под името UTF-32, позволяваща да се съхранят повече от един милиард уникални символи, което беше най-важната стъпка при дешифрирането на текстове.

Въпреки това, първата универсална таблица с кодови символи Unicode UTF-32 не е широко разпространена. Основната причина беше излишното съхраняване на информация. Бързо се изчислява, че за страни, които използват латинската азбука, кодирана с нова универсална електронна таблица, текстът ще заема четири пъти повече място, отколкото използването на разширената ASCII таблица.