Формално файлът с дизайн се съдържа в PHP, подобен на файл, но поставя прочетеното съдържание в низ, а не в масив от редове и ви позволява да зададете промяна във файла, от който да започнете да четете.
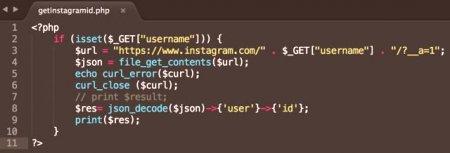
Синтаксис и пример за използване

Обикновено по-опростена версия на файла получава съдържание PHP се използва:

. Посоченият указан URL адрес. Всъщност, страница
е представена от PHP phpinfo () конструкт, т.е. текстът от три реда не се чете и резултатът от тази функция.
 Както може да се види, резултатът е пълна страница, докато PHP се конструира съдържанието на файла при http (http) е прочел и записал вътрешното съдържание на тази страница в променливата $ cLine.
Трябва да се има предвид, че използването на параметъра $ context отваря големи възможности.
Както може да се види, резултатът е пълна страница, докато PHP се конструира съдържанието на файла при http (http) е прочел и записал вътрешното съдържание на тази страница в променливата $ cLine.
Трябва да се има предвид, че използването на параметъра $ context отваря големи възможности.
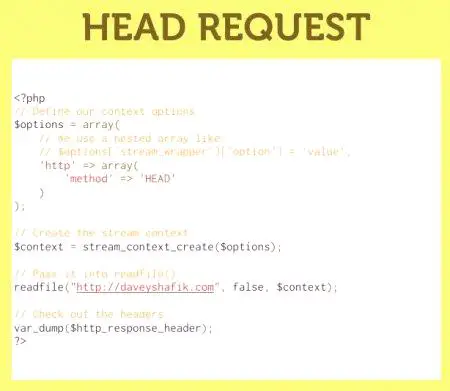 При нормална практика, използването на всички параметри с изключение на $ filename не е популярно правило. Въпреки това, стойността е създаденаСтруктурата stream_context_create () и използвана като параметър $ context, ви позволява да пишете доста сложни алгоритми за получаване на необходимата информация. Различните файлови системи, опаковките изискват различни настройки и опции за описване на контекста. Тя може да бъде създадена с помощта на конструкции stream_context_create (stream_context_set_option, stream_context_set_params).
Вместо специфичен URL адрес, параметърът $ filename може да бъде представен с името на променливата. Това ви позволява да анализирате съдържанието на сайтовете в автоматичен програмируем режим, да разберете имената на страниците, да идентифицирате връзките, да получите необходимата информация.
При нормална практика, използването на всички параметри с изключение на $ filename не е популярно правило. Въпреки това, стойността е създаденаСтруктурата stream_context_create () и използвана като параметър $ context, ви позволява да пишете доста сложни алгоритми за получаване на необходимата информация. Различните файлови системи, опаковките изискват различни настройки и опции за описване на контекста. Тя може да бъде създадена с помощта на конструкции stream_context_create (stream_context_set_option, stream_context_set_params).
Вместо специфичен URL адрес, параметърът $ filename може да бъде представен с името на променливата. Това ви позволява да анализирате съдържанието на сайтовете в автоматичен програмируем режим, да разберете имената на страниците, да идентифицирате връзките, да получите необходимата информация.
 Можете да създадете свой собствен анализатор на сайт, търсачка и да напишете програми за обработка на разпределена информация. Задачата е актуална, интересна и практична.
Няма проблем какво точно да прочетете файла. В следващия, сложен дизайн, съдържанието на файла php е пример за това, че файлът "vordovsky" може да бъде прочетен без проблеми:
Можете да създадете свой собствен анализатор на сайт, търсачка и да напишете програми за обработка на разпределена информация. Задачата е актуална, интересна и практична.
Няма проблем какво точно да прочетете файла. В следващия, сложен дизайн, съдържанието на файла php е пример за това, че файлът "vordovsky" може да бъде прочетен без проблеми:
 Тук е сложен документ, който се използва за тестване на библиотеката PHPOffice /PHPWord. Файлът MS Word (* .docx) е известен като zip архив, в който информацията се основава на стандарта Open XML. Обикновено, файловете с документи са достатъчно големи и сложни, но файлът съдържа структурата на съдържанието, която PHP може да обработи безпроблемно. Спецификата на този пример е, че обработката на документи е само средство за библиотеката PHPOffice /PHPWord, която не ви позволява да получите необходимите възможности и просто не е възможно да четете файла последователно. вДаденият документ всички негови елементи (думи, параграфи, формули, чертежи, правописни елементи) са описани чрез поредица от тагове, а някои могат да бъдат представени чрез последователност от вложени обекти.
Тук е сложен документ, който се използва за тестване на библиотеката PHPOffice /PHPWord. Файлът MS Word (* .docx) е известен като zip архив, в който информацията се основава на стандарта Open XML. Обикновено, файловете с документи са достатъчно големи и сложни, но файлът съдържа структурата на съдържанието, която PHP може да обработи безпроблемно. Спецификата на този пример е, че обработката на документи е само средство за библиотеката PHPOffice /PHPWord, която не ви позволява да получите необходимите възможности и просто не е възможно да четете файла последователно. вДаденият документ всички негови елементи (думи, параграфи, формули, чертежи, правописни елементи) са описани чрез поредица от тагове, а някои могат да бъдат представени чрез последователност от вложени обекти.
Ако вземете примера на документ (* .docx) с таблици, ситуацията изобщо не се разрешава, ако обработвате файла последователно. Изисква поне два пътя през тялото на документа, ако не отидете например, например, когато таблиците са вградени един в друг.
Ако четенето на сложни файлове не създава проблеми, тогава проблемът е работа с прости файлове. Първо трябва да вземете аксиомата: структурата на файла получава съдържание, което PHP чете правилно. Дори и да не използвате тези или други параметри, най-простият вариант на неговото приложение винаги ще работи както трябва. Трудностите причиняват ъглови скоби и кодиране на файлове. Работата в алгоритъма трябва да се различава от показването на резултата в прозореца на браузъра. Линията
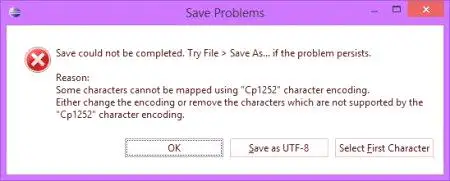 Следващият момент: кодиране на файлове. Не винаги един прост текстов файл не създава проблеми. Ако се чете текстова информация, наличието на n букви може да създаде някои трудности
Следващият момент: кодиране на файлове. Не винаги един прост текстов файл не създава проблеми. Ако се чете текстова информация, наличието на n букви може да създаде някои трудности
Опции и контекстни настройки
Масова обработка на страници
Четене на текстови файлове
Ако вземете примера на документ (* .docx) с таблици, ситуацията изобщо не се разрешава, ако обработвате файла последователно. Изисква поне два пътя през тялото на документа, ако не отидете например, например, когато таблиците са вградени един в друг.
Проблеми с кодирането и специалните символи
- $ cLine = scChangeLTGT ($ cLine) - извиква функцията за трансформиране на двойка ъглови скоби в специалния знак на "" фигурата с пример на файл на отдела. Как да напишем тази функция не е от съществено значение, но е важно да се има предвид, че информацията за четене може да съдържа XML и HTML тагове и това изисква специално внимание.
. $ cLine = iconv ('UTF-8', 'CP1251',$ cLine). В този контекст използването на функцията iconv () с правилната посока на преобразуване е не само свързано с PHP, "получавате съдържание на файла http: //" за четене на страницата на даден сайт, но и когато се чете обикновен локален файл. Ако резултатът от четенето е "невидим", първото нещо е да проверите кодирането на знаците.