Азбуката в компютърните науки се нарича система от знаци, чрез която можете да подадете информационно съобщение. За да разберем същността на тази дефиниция, даваме няколко допълнителни теоретични факти:
Всички съобщения се състоят от азбука. Например тази статия е съобщение. Тогава тя се състои от символите на руската азбука.
Под символа можем да разберем най-маловажната част от азбуката. Също така, неделимите частици се наричат атоми. Символите в руската азбука са "а", "б", "в" и т.н.
На теория азбуката не е задължително да се кодира вече. Например в отпечатаната книга символите в азбуката означават, че те нямат кодиране.
Но на практика ние имаме следното: компютърът не разбира какво са буквите. Следователно, за предаването на информационно съобщение, то трябва първо да бъде кодирано на език, разбираем за компютъра. За да продължите напред, трябва да въведете допълнителни условия.
Каква е силата на азбуката
Под силата на азбуката имаме предвид общия брой символи в него. За да разберете каква е силата на азбуката, просто трябва да преброите броя на знаците в нея. Нека разберем. За руската азбука силата на азбуката е 33 или 32 знака, ако не използвате "e". Да приемем, че всички символи в нашата азбука са също толкова вероятни. Това предположение може да се разбира като: да предположим, че имаме торба с подписаникубчета. Броят на кубчетата в него е безкраен и всеки един е подписан само с един знак. След това, с равномерно разпределение, без значение колко получаваме кубчетата от чантата, броят на кубчетата с различни символи ще бъде един и същ, или ще се стреми да го направи с нарастването на броя на кубовете, които получаваме от чантата.
Оценка на тежестта на информационните съобщения
Преди почти сто години американският инженер Ралф Хартли извлече формула, чрез която можете да оцените количеството информация в съобщението. Неговата формула работи за вероятностни събития и изглежда така: i = log 2 M Където i - броят на неделимите информационни атоми (битове) в съобщението, "M" - силата на азбуката. Нека да продължим. С помощта на математически преобразувания можем да определим, че мощността на азбуката може да се изчисли по следния начин:
M = 2 i Тази формула като цяло определя връзката между броя на еднакво вероятното събитие "M" и количеството информация "i".
Изчисляваме силата
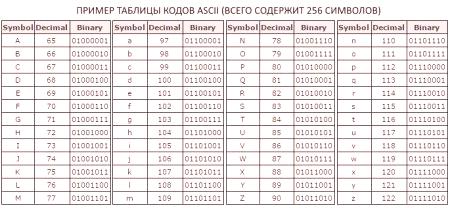
Най-вероятно вече знаете от училищния курс по компютърни науки, че в съвременните компютърни системи, изградени върху архитектурата на фон Нойман, се използва бинарна система за кодиране. Той кодира приложения и данни. За да се представи текстът в изчислителната система, използвайте единен код от осем цифри. Следователно се приема, че единният код съдържа фиксиран набор от елементи - 0 и 1. Стойностите в такъв код се определят с определен ред на тези елементи. С осем-битов код можем да кодираме съобщения с 256 бита, съгласно формулатаХартли: М 8 = 2 8 = 256 бита информация. Такава ситуация с двоичния код за кодиране на символи исторически се формира. Но теоретично можем да използваме други азбуки за представяне на данни. Например, в четирибуквен азбука, всеки знак ще има тегло не едно, а две бита, в осем цифри - 3 бита и така нататък. Това се изчислява с помощта на двоичния логаритъм, даден по-горе (i = log 2 M). Тъй като в азбуката от 256 бита се присвояват осем бинарни цифри, за да се посочи единичен знак, беше решено да се въведе допълнителна мярка от информация - байт. Един байт съдържа един символ от ASCII кодовата таблица и съдържа осем бита.
Как се измерва информацията
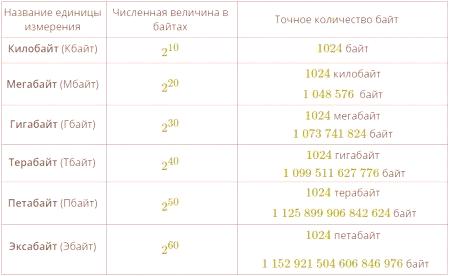
Осемстотинте кодиране на текст, използвано в ASCII кодовата таблица, ви позволява да съдържате основния набор от латиница и кирилица както в горния, така и в долния регистър, цифрите, препинателните символи и други основни символи. За да се измерват големи обеми от данни, използвайте специални префикси за думите байтове и битове. Такива конзоли са дадени в таблицата по-долу:
Много хора, които са изучавали физика, отричат, че би било рационално да се използват класически съгласни за обозначаване на информационни единици (като кило и мега), но в действителност това не е напълно правилно, тъй като тези префикси към стойностите обозначават умножението на едно или друго. степен десет, когато в компютърните науки навсякъде се използва двоична система от измервания.
Правилни наименования на единиците за измерване на данни
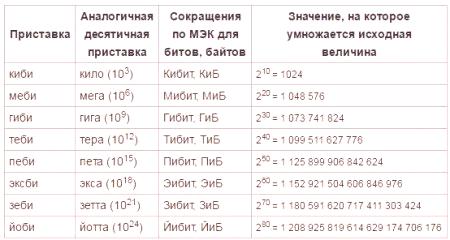
С цел да се елиминиратПрез март 1999 г. Международната комисия по електротехника одобри нови единици за единиците, използвани за определяне на количеството информация в електронното изчисление. Такива представки са "mebia", "kibi", "gibi", "tebi", "ексби", "pety". Докато тези единици все още не се реализират, вероятно е необходимо време, за да се приложи този стандарт и да го направи широко разпространено. Как да направим преход от класически единици към ново одобрени, можете да определите в следната таблица:
Да предположим, че имаме текст, съдържащ K символи. След това, използвайки азбучния подход, можете да изчислите количеството информация, съдържаща се в него. Тя ще бъде равна на продуктивната мощност на азбуката към информационното тегло на един знак в него. Чрез формулата Хартли знаем как да изчислим количеството информация чрез двоичен логаритъм. Ако приемем, че броят на знаците в азбуката е N, а броят на символите в информационния запис на съобщението е K, получаваме следната формула за изчисляване на обема на съобщенията: V = K? Азбучен подход показва, че обемът на информацията ще зависи само от капацитета на азбуката и размера на съобщенията (т.е. броя на символите в него), но няма да бъде свързан със семантично съдържание за дадено лице.
Примери за изчисляване на мощността
Класовете по информатика често задават задачата да намерят силата на азбуката, дължината на съобщението или обема на информацията. Ето една от следните задачи:"Текстов файл заема 11 KB на дисково пространство и съдържа 11,264 знака. Определяне на капацитета на азбука текстовия файл в." Как ще се види по-долу решения.
По този начин, способността на азбуката символи 256 носи само 8 бита информация в областта на науката се нарича байт. Байт 1 описва таблица ASCII характер, които, ако се замислите, не много.
Един байт - много или малко?
Съвременните информационни хранилища центрове за данни, като Google и Facebook имат не по-малко от десет петабайта информация. Точната сума на данни, обаче, ще бъде трудно да се изчисли, дори от себе си, защото тогава ще трябва да се спрат всички сървъри и потребителите достъп в близост до рекорда и редактирате личните си данни.
Но да си представим тези невъобразими количества данни трябва да бъдат ясно разбира, че тя се състои от малки части. Трябва да се разбере какъв е капацитетът на азбуката (256) и колко бита, съдържащи 1 байт на информация (както си спомняте, 8).