Компресирането е частен случай на кодиране, чиято основна характеристика е, че полученият код е по-малък от оригинала. Процесът се основава на търсенето на повторения в информационната серия и запазването само на едно заедно с броя на повторенията. Така например, ако последователността се появи във файл като "AAAAAA", заемащ 6 байта, той ще бъде записан като "6A", който заема 2 байта в алгоритъма за компресия на RLE.
История на процеса
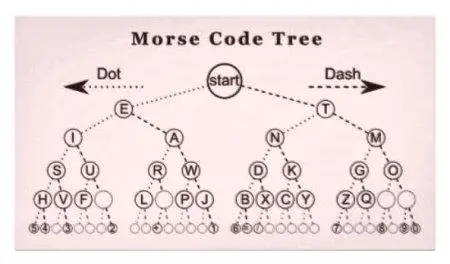
Морзевият код, изобретен през 1838 г., е първият известен случай на компресиране на данни. По-късно, когато през 1949 г. мейнфрейм компютрите започнаха да придобиват популярност, Клод Шанън и Робърт Фано измислиха кодирането, наречено на авторите - Шанън-Фано. Това криптиране присвоява символни кодове на масив от данни за теория на вероятностите.
Едва през 70-те години, с появата на интернет и онлайн съхранение, бяха въведени пълноценни алгоритми за компресиране. Кодовете на Huffman се генерират динамично въз основа на входната информация. Ключовата разлика между кодирането на Шанън-Фано и кодирането на Хафман е, че в първото дърво на вероятностите е било изградено отдолу нагоре, създавайки неоптимален резултат, а във втория - отгоре надолу. През 1977 г. Авраам Лемпел и Яков Зев издават своя иновативен метод LZ77, използвайки по-модернизиран речник. През 1978 г. същият екип от автори издава подобрен алгоритъм за компресия LZ78. Кой използва новия речник, анализира входящите данни и генерира статичен речник, а не динамичен, както в 77версия.
Форми на изпълнение на компресия
Компресирането се извършва от програма, която използва формула или алгоритъм, който определя как да се намали размерът на данните. Представете си, например, низ от битове с по-малък низ от 0 и 1, използвайки речник за преобразувания или формула. Компресията може да бъде проста. Например, като изтриете всички ненужни символи, вмъкнете дублиращ се код, за да укажете повтарящ се низ и да замените по-малък растер. Алгоритъмът за компресиране на файлове може да намали текстов файл до 50% или много повече. За предаване, процесът се изпълнява в предавателен блок, включващ данни в заглавната част. Когато информацията е изпратена или получена по интернет, архивните файлове, самостоятелно или в комбинация с други големи файлове, могат да бъдат предадени в ZIP, GZIP или друг "редуциран формат". Файл от 20 мегабайта (МБ) ще отнеме 10 МБ пространство, което ще доведе до по-малко време, прекарано от мрежовите администратори за съхраняване на бази данни.
Оптимизира производителността на архивиране. ]Почти всеки файл може да бъде въведен но е важно да изберете технологията, която искате за конкретен тип файл, в противен случай файловете могат да бъдат намалени, но общият размер няма да се промени.Прилагат се два типа методи - алгоритми за компресия без загуби и без загуби. Първият ви позволява да възстановите файловете в първоначалното състояние, без да загубите един бит информация в компресиран файл. Вторият е типичен подходизпълними файлове, текст и електронни таблици, където загубата на думи или числа ще промени информацията.
Компресията за загуба трайно премахва бита от данни, които са излишни, незначителни или незабележими. Той е полезен с графики, аудио, видео и изображения, където премахването на някои битове практически няма забележим ефект върху представянето на съдържанието.
Алгоритъм на компресия на Huffman
Този процес може да се използва за "намаляване" или криптиране. Тя се основава на присвояване на кодове с различна дължина от битове, съответстващи на всеки повтарящ се символ, колкото повече такива повторения, толкова по-висока е степента на компресия. За да възстановите изходния файл, трябва да знаете присвоения код и неговата дължина в битове. По същия начин се използва приложение за шифроване на файлове. Процедура за създаване на алгоритми за компресиране на данни:
Изчислете колко пъти всеки символ се повтаря във файл за "редукция". Създаване на свързан списък с информация за символи и честоти. Извършва сортирането на списъка от най-малките до най-големите, в зависимост от честотата. Конвертиране на всеки елемент от списъка в дърво. Комбинирайте дърветата в едно, като първите две образуват нова. Добавя честотите на всеки клон към нов елемент на дърво. Вмъкване на ново в желаното място в списъка, в зависимост от количеството получени честоти. Присвояване на нов двоичен код за всеки символ. Ако се вземе нулевия клон, към кода се добавя нула и ако се добави първият клон, единицата се добавя. Файлът е кодиран всъвпадение с нови кодове. Например характеристиките на алгоритмите за компресия за краткия текст: "ata la jaca a la estaca" Избройте колко пъти се появява всеки символ и създавате свързан списък: "
,Подреждане по честота от най-ниско до по-високо: e ,
,
), j
, s
, c
, l
, t
,
, a
Както виждате, коренният възел на дървото се създава, след което се присвояват кодовете.
И остава само да се пакетират бита в групи по осем, т.е. байтове:
01110010
11010101
00010010
11010101
11110111
)
0xd5

0xFB
0x12
0xd5
0xF7
91)
0xB9
0x80
Всички осем байта и изходният текст бяха 23.
Демонстрация на библиотеката LZ77
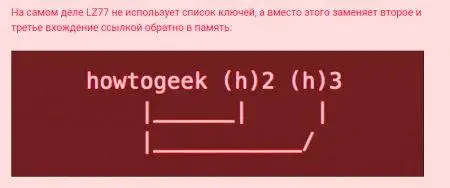
Да разгледаме алгоритъма LZ77 на примерен текст «howtogeek». Ако го повторите три пъти, то ще го промени по следния начин.
След това, когато иска да прочете текста обратно, той ще замени всеки случай (h) с "howtogeek", връщайки се към оригиналната фраза. Той демонстрира алгоритъма за компресиране на данни без загуби, тъй като входните данни са същите като получените данни.
Това е идеален пример, когато по-голямата част от текста е компресиран с няколко символа. Например, думата "това" ще бъде кратка, дори ако се появява в такива думи като "това", "тяхното" и "това". С повтарящи се думи можете да получите огромни коефициенти на компресия.Например, текст с думата "howtogeek", повторен 100 пъти размера на три килобайта, с компресия ще отнеме само 158 байта, т.е. с 95% "намаление".
Това, разбира се, е доста краен пример, но ясно показва свойствата на алгоритмите за компресия. По принцип това е 30-40% от текстовия формат на ZIP. Алгоритъмът LZ77 се прилага за всички двоични данни, а не само за текст, въпреки че последният е по-лесно да се компресира чрез повтарящи се думи.
Дискретна косинусна трансформация на изображения
Компресирането на видео и аудио работи съвсем различно. За разлика от текста, който изпълнява алгоритми за компресия без загуби, а данните няма да бъдат загубени, изображенията се "намаляват" със загуби, а колкото повече%, толкова повече загуби. Това води до ужасните изгледи на JPEG файловете, които хората свалят, обменят и правят скрийншоти няколко пъти. Повечето снимки, снимки и други съхраняват списък с числа, всеки от които представлява един пиксел. JPEG ги съхранява чрез алгоритъм за компресиране на изображения, наречен дискретна косинусна трансформация. Той представлява набор от синусоидални вълни, които се състоят от различна интензивност. Този метод използва 64 различни уравнения, а след това Huffman кодиране, за да намали още размера на файла. Подобен алгоритъм за компресиране на изображения дава изключително висока степен на компресия и го намалява от няколко мегабайта до няколко килобайта, в зависимост от изискваното качество. Повечето снимки са компресирани, за да запазят времето за изтегляне, особено за мобилни потребителилош пренос на данни.
Видеото работи малко по-различно от изображението. Обикновено алгоритмите за компресиране на графична информация се използват от това, което се нарича "междуредово компресиране", което изчислява промените между всеки кадър и ги записва. Например, ако има относително неподвижно изображение, което отнема няколко секунди от видеото, то ще бъде "намалено" до едно. Интерком компресията осигурява цифрова телевизия и уеб видео. Без него, видеото тежеше стотици гигабайта, което е повече от средния твърд диск през 2005 година. Компресирането на аудиото много прилича на компресиране на текст и изображения. Ако JPEG изтрие детайлите на изображение, което е невидимо за човешкото око, компресията на звука прави същото за звуци. MP3 използва битрейт, вариращ от по-ниските 48 и 96 kbit /s (долна граница) до 128 и 240 kbps (доста добра) до 320 kbps (висококачествен звук), и можете да чуете разликата само с много добри слушалки. Има аудио кодеци без загуби, основната от които е FLAC и използва кодиране LZ77 за предаване на звук без загуби.
Формати за декомпресия на текст
Обхватът на библиотеките за текст се състои главно от алгоритъм за компресиране на данни без загуби, с изключение на крайните случаи за данни с плаваща запетая. Повечето компресорни кодеци включват "намаление" на LZ77 Huffman и аритметичното кодиране. Те се използват след други инструменти, за да изтласкат още няколко процента компресия.
Изпълнява кодираните стойности като знак, последван от дължината на цикъла. Можете да възстановите изхода правилнопоток. Ако дължината на серията